サポートベクターマシン(SVM)
サポートベクターマシン(Support Vector Machine:SVM)は2クラス分類識別器の一種ある。
その大きな特徴として次の三つがあげられる。
- マージン最大化という方針で識別平面を決定するので高い汎化能力が期待できる。
- 学習がラグランジュ未定乗数法により二次計画問題に帰着され、局所最適解が必ず広域最適解となる。
- 識別対象の空間に対する事前知識を反映した特徴空間を定義することで、その特徴空間上で線形識別を行える。 さらにその特徴空間上での内積を表したカーネルと呼ばれる関数を定義することにより、明示的に特徴空間への 変換を示す必要がない。
以下に簡単に説明していく。
1.マージン最大の識別平面
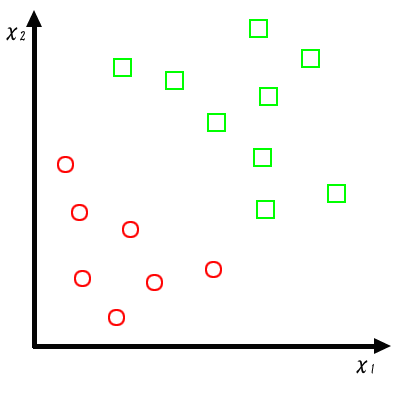
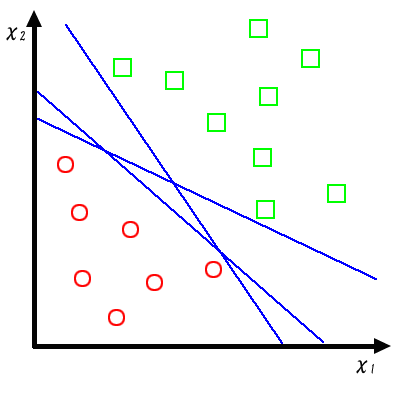
図1のように2次元ベクトルで表される空間上にあるパターンを線形に識別する問題を考えてみる。 ○と □はそれぞれ別のクラスに属するものとする。 一般にパターン認識の問題では、パターンをどちらのクラスに含まれるかの境界を決めることが目標となる。 この境界を識別平面と呼ぶ。この例では、2次元空間上のパターン認識なので識別平面として1本の直線を 決めることになる。さて、図2を見ると示されているパターンをきちんと分けることができる直線は無数に 引くことができる。
 |
 |
| 図1 | 図2 |
ところでパターン認識の目的は、一般に既知のパターンだけでなく、未知のパターンに対しても
正しく識別する必要がある。この点から考えると識別平面は、それぞれのクラスに属する既知のパターンの
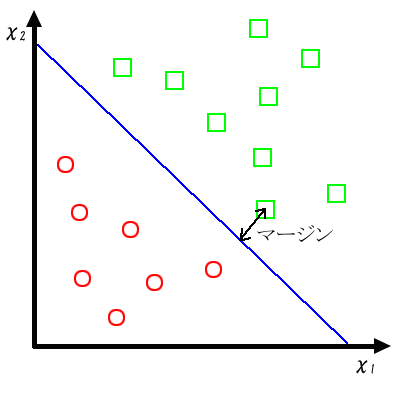
ちょうど「真ん中」を通るものが良いであろう。このちょうど「真ん中」を通るとは、図3の様に識別平面から
もっとも近い既知のパターンとの距離(マージンと呼ぶ)を最大になるようにとることを意味する。
統計的にもこの識別平面の採り方が正しく識別する確率がもっとも高くなることが示されている。
SVMではこのマージンを最大化する識別平面をとるように設計されており、未知のパターンに対しても
正しく識別する確率が高いこと(高い汎化能力)が期待できる。
 |
| 図3 |
2.パラメータの最適化(学習)
一般に学習器は既知のパターンを用いて、学習器のパラメータの値を更新していくことで識別平面を
決定していく。この過程を学習と呼ぶ。誤差逆伝搬法を用いたニューラルネットワークなどではこの学習の過程で、
「局所最適解」という問題が発生する。これは、学習器のパラメータが張る空間全体でもっとも良い値(広域最適解)
ではなく、一部の範囲でのもっとも良い値(局所最適解)で学習が止まってしまうという問題である。
SVMにおいては、ラグランジュの未定乗数を用いることにより学習の過程が最終的に二次最適化問題に帰着する。
二次最適化問題は、局所最適解が必ず広域最適解に等しいという性質があるので、SVMでは局所最適解の問題は
発生しない。
3.特徴空間とカーネル
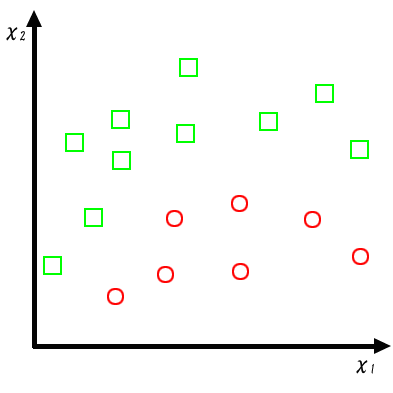
パターン認識の問題は線形に識別できるものばかりではない。たとえば、図4のようなパターンが 示されている場合のパターン認識を考えてみる。この場合、このままではどのような直線の引き方をしても、 正しく識別を行える識別平面はできない。ここで、パターンをX2の値を (X1+1)倍するような関数で変換してみるとパターンの射影は図5の様になり、 直線で正しく識別を行える識別平面を決定できるようになる。
 |
 |
| 図4 | 図5 |
このように、元のパターンの空間から、何らかの関数を用いて変換された先の空間を 特徴空間と呼ぶ。この特徴空間への変換に用いる関数に、識別したいパーターンに対する事前知識を 反映させることで高い汎化能力が期待できる。SVMではこの特徴空間上での線形識別を行う方法として、 変換関数の代わりにカーネル関数と呼ばれる関数を定義する。このカーネル関数とは、特徴空間上での 二つのパターンの内積を表すものであり、K(a,b)のような形で表され、 この関数を定義すれば明示的に変換関数を定義する必要がないのもSVMの特徴のひとつである。